- 更新日: 2016年12月16日
- 開発記録
JavaScriptで英単語の原形を取得できるライブラリを公開しました
英単語の名詞の複数形や動詞の活用形から、その単語の原形を取得できる JavaScript のライブラリを公開しました。
desks → desk
better → good
written → write
などのように、英単語の変化形からその原形を取得できます。
 画像付き英語辞書 Imagict | 英単語をイメージで暗記
画像付き英語辞書 Imagict | 英単語をイメージで暗記サンプルのデモページ
サンプルで添付している html/lemmatizer_sample.html のデモページです。
適当に英語の単語の変化形を入力、品詞を選択して(未選択でも可)、「Search Lemma」ボタンを押しますと、入力単語の原形を出力します。
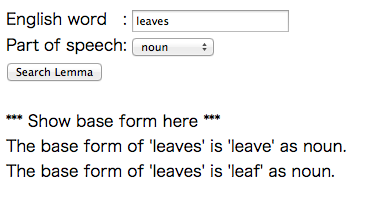
使い方と取得できる単語の原形の戻り値
実際のメソッドの使い方や、取得できる戻り値は以下の通りです。js/lemmatizer.js をロード後、Lemmatizer インスタンスを生成して、Lemmatizer#lemmas か Lemmatizer#only_lemmas メソッドを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// initialize Lemmatizer. var lemmatizer = new Lemmatizer(); // retrieve a lemma with a part of speech. // you can assign 'verb' or 'noun' or 'adj' or 'adv' as a part of speech. lemmatizer.lemmas('desks', 'noun'); // => [ ['desk', 'noun'] ] lemmatizer.lemmas('talked', 'verb'); // => [ ['talk', 'verb'] ] lemmatizer.lemmas('coded', 'verb'); // => [ ['code', 'verb'] ] // of course, available for irregular iflected form words. lemmatizer.lemmas('went', 'verb'); // => [ ['go', 'verb'] ] lemmatizer.lemmas('written', 'verb'); // => [ ['write', 'verb'] ] lemmatizer.lemmas('better', 'adj'); // => [ ['good', 'adj'] ] // when multiple base forms are found, return all of them. lemmatizer.lemmas('leaves', 'noun'); // => [ ['leave', 'noun'], ['leaf', 'noun'] ] // retrieve a lemma without a part of speech. lemmatizer.lemmas('sitting'); // => [ ['sit', 'verb'], ['sitting', 'noun'], ['sitting', 'adj'] ] lemmatizer.lemmas('oxen'); // => [ ['oxen', 'noun'], ['ox', 'noun'] ] lemmatizer.lemmas('leaves'); // => [ ['leave', 'verb'], ['leave', 'noun'], ['leaf', 'noun'] ] // retrieve only lemmas not including part of speeches in the returned value. lemmatizer.only_lemmas('desks', 'noun'); // => [ 'desk' ] lemmatizer.only_lemmas('coded', 'verb'); // => [ 'code' ] lemmatizer.only_lemmas('priorities'); // => [ 'priority' ] lemmatizer.only_lemmas('leaves'); // => [ 'leave', 'leaf' ] |
【2015/01/31 追記】
2015/01/30のv0.0.2へのアップデートに伴い、上記のサンプルコードを修正しました。
【追記ここまで】
【2015/02/02 追記】
lemmatizer の精度向上のためのコミットに伴い、上記のサンプルコードを修正しました。
【追記ここまで】
Lemmatizer#lemmas は、[単語の原形, 品詞] のペアの配列を返します。Lemmatizer#only_lemmas は、戻り値に品詞を含まず単語の原形のみの配列を返します。いずれも、複数の原形が見つかった場合は、それら全てを配列として返す仕様です。
品詞の指定としては、verb(動詞), noun(名詞), adj(形容詞), adv(副詞)の4つのいずれかを指定できます。 また、品詞の指定はあってもなくてもOKです。
品詞を指定した場合は、その品詞での単語の原形を取得します。Lemmatizer#lemmas で品詞を指定しなかった場合は、見つかったそれぞれの品詞での原形を配列で返します。Lemmatizer#only_lemmas の場合は、戻り値に品詞の情報は含まれません。
より詳しい設置法〜使い方は GitHub の README をご参照お願いします。
先日使ってみました Ruby Lemmatizer | yohasebe.com を参考にしましたが、言語も Ruby と JavaScript で違いますし、中身の実装はだいぶ異なるものとなっています。
Ruby Lemmatizer は見つかった原形を1つだけ返す仕様ですが、JavaScript Lemmatizer はより柔軟性を持たせて使えるように、見つかった複数の単語の原形を全てを返すように、戻り値を配列で返すようにしました。
英単語の原形を取得するRuby Lemmatizerの使い方 | EasyRamble
以上ですが、需要があるかどうか分かりませんけども、ご利用お待ちしております!






- 開発記録 の関連記事
- Mastodon(マストドン)をブログ風に保存するサービスを作った
- Wunderlistからリマインダー(iPhone/iCloud)への移行ツールを作りました!
- 指定の曜日から日付を取得するツール(JavaScript)
- 書評や商品レビューのブログ記事のみにGoogle検索を絞り込むブックマークレット
- サクサクひける!ポップアップ辞書Chrome拡張(英和/英英辞典)を公開しました
- ImagictでBingoされた英単語をつぶやくTwitter botを作成しました
- jQuery(JavaScript)でマウス座標やウィンドウサイズを取得して確認するツール
- JavaScriptでcollapsed rangeオブジェクトを可視化するツールを作った
- SimString を用いたスペルミス訂正機能
- Imagict 開発日誌のブログを始めました
- 初回公開日: 2015年1月27日
- 1件のコメント
はじめまして。
今、英文記事から単語を抜き出し、その単語を原型の形で単語リストを作ろうとしています。
で、JavaScript Lemmatizerが使えるかも!と思って導入しようとしているのですが、
var lemmatizer = new Lemmatizer();
を実行すると以下のエラーとなってしまいます。
———-コンソールログ———-
VM33137:1 Uncaught SyntaxError: Unexpected token < in JSON at position 0
at JSON.parse ()
at Lemmatizer.fetch_data (lemmatizer.js:191)
at Lemmatizer.setup_dic_data (lemmatizer.js:165)
at new Lemmatizer (lemmatizer.js:86)
———————————-
今、Chromeのバージョンが、
「バージョン: 81.0.4044.122(Official Build) (64 ビット)」
です。
そもそも、今のバージョンで動くのかどうかってわかるでしょうか?